Node Aggregation
The node aggregation algorithm repeatedly clusters the nodes of a given graph and creates a hierarchical structure of clusters. It achieves this by intelligently selecting appropriate clustering algorithms and applying them repeatedly. The result can, for example, be used to collapse regions to simplify interactively browsing large graphs. Refer to the Large Graph Aggregation on how to integrate the aggregation result for such a use case.
The result of a node aggregation algorithm is a tree of elements of type NodeAggregate. Each NodeAggregate consists of a collection of child aggregates, which, together with the NodeAggregate itself, represent a cluster of graph nodes. The corresponding graph node of an aggregate can be accessed by each aggregate’s node property. Conversely, the NodeAggregationResult provides a mapping from nodes to their respective aggregate, exposed by the aggregateMap. Also, the NodeAggregationResult provides the root of the resulting tree.
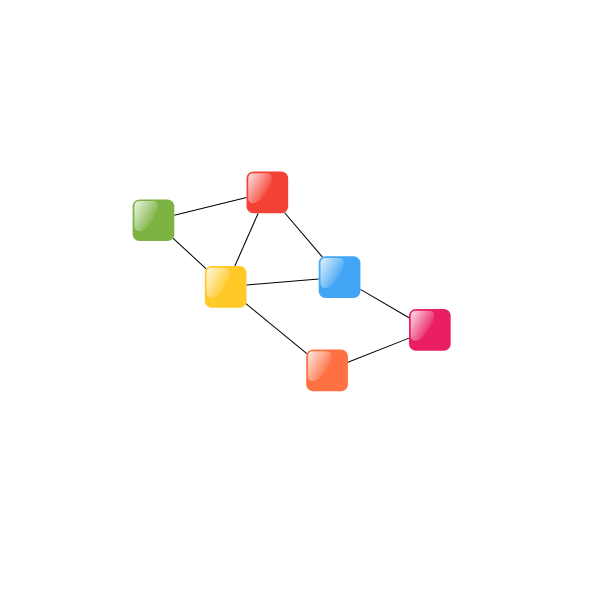
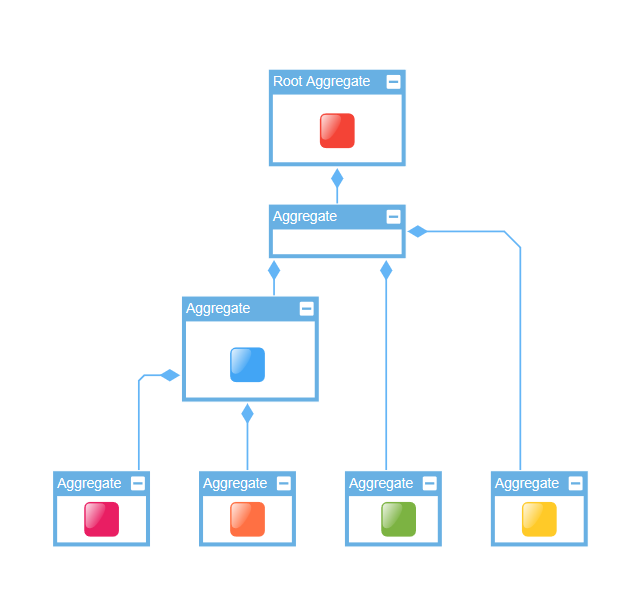
An NodeAggregate, together with its child nodes, represents a cluster. In the example above, the NodeAggregate containing the blue node, together with its child aggregates, forms a cluster which contains the blue, magenta, and orange node.
Calculating a Node Aggregation shows how to structurally aggregate the nodes of a graph.
// prepare the node aggregation algorithm
const algorithm = new NodeAggregation({
// determine substructures according to the graph structure, not the geometry/coordinates
aggregationPolicy: NodeAggregationPolicy.STRUCTURAL
})
// run the algorithm
const result = algorithm.run(graph)|
Note
|
Note that some aggregates are purely virtual tree nodes that do not contain a graph node. The leaves of the aggregate tree always contain a graph node. nodesOnlyOnLeaves can be set to prevent non-leaf aggregates from containing a node. |
The aggregation algorithm can be configured in several ways. The preferred resulting cluster sizes can be set by minimumClusterSize and maximumClusterSize. However, these are hints, and the algorithm does not guarantee that the resulting clusters will strictly adhere to these values.
By setting the aggregation policy, the algorithm can be configured to operate either on the structural properties of the given graph, such that groups of nodes that are highly interconnected are likely placed into the same cluster, or alternatively, to take the positions of nodes into account, such that nodes that are geometrically close to each other are likely clustered together.
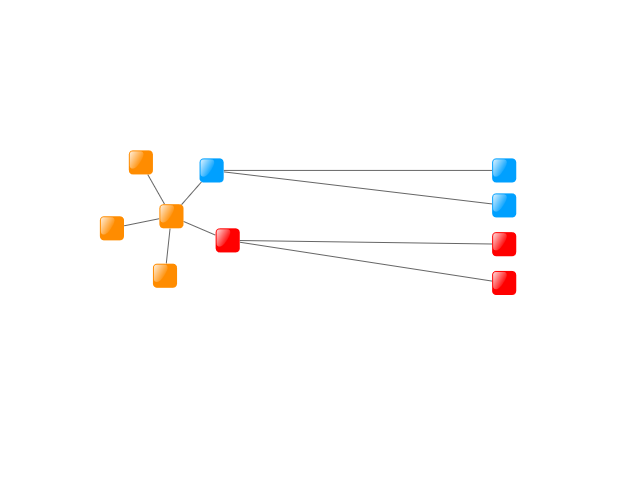
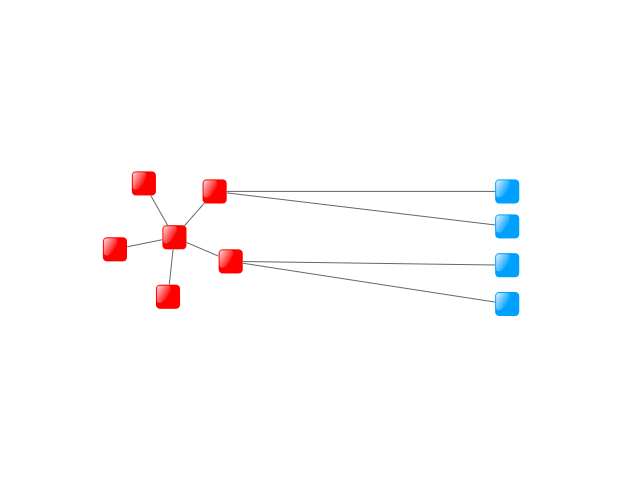
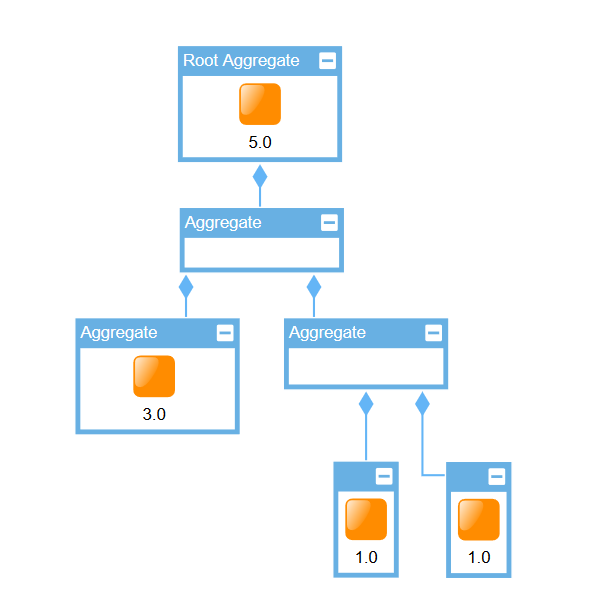
Node weights can be set to influence the algorithm to place certain nodes closer to the root of the aggregation hierarchy. These weights can be set via a mapper, as shown in Setting node weights. For more information about mapping items, see Associating Data with Graph Elements. If specific nodes are to be placed at the top of the hierarchy, they can be directly set as top-level nodes.
// creates a mapping that sets the weight of a node to the length of it's label
// placing nodes with long text higher up the hierarchy
nodeAggregation.nodeWeights.mapperFunction = (node) =>
node.labels.first()!.text.length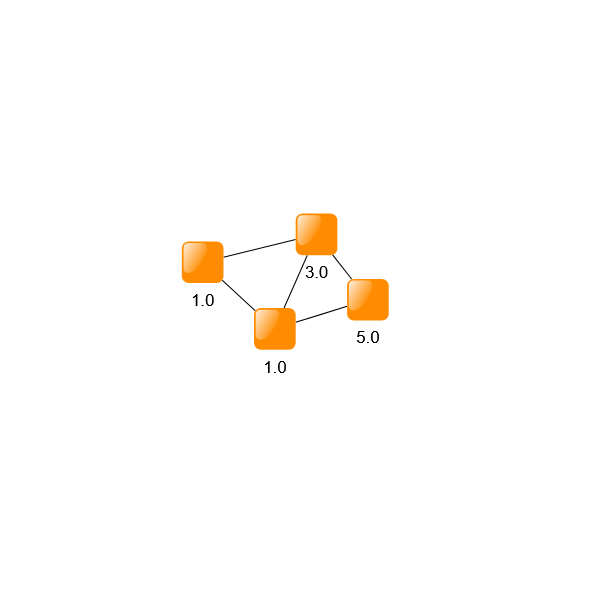
It is also possible to exclude certain nodes from being clustered together. This can be controlled by associating each node with an arbitrary type object via nodeTypes. Property nodeTypePolicy defines how node types are handled by the algorithm. Nodes with different types are then prevented from being clustered together.
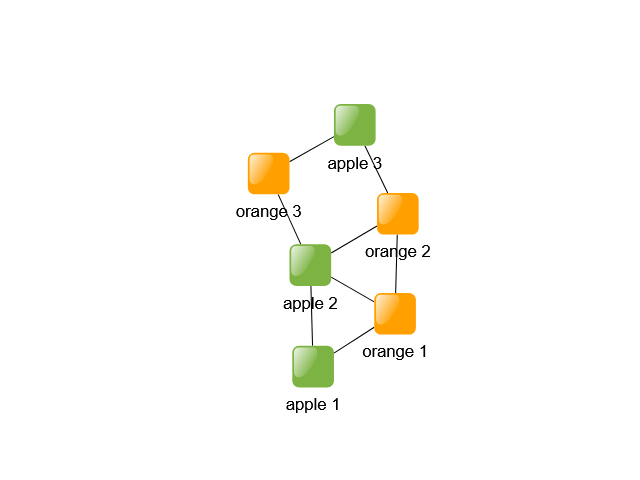
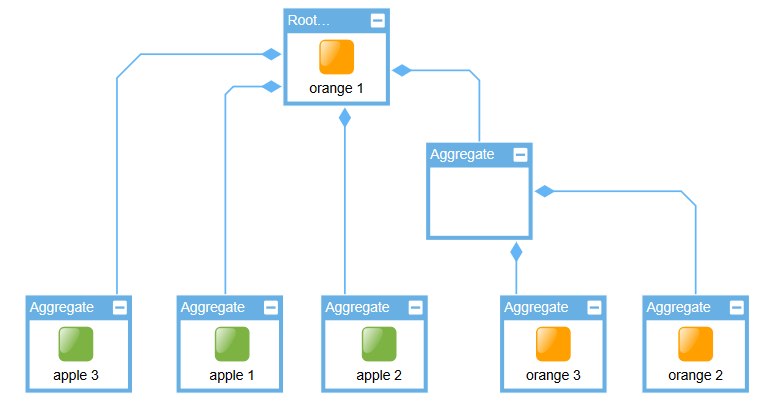
// creates a mapping that associates a node to it's color
nodeAggregation.nodeTypes.mapperFunction = (node) => node.tag?.color
// sets how the algorithm handles the types
nodeAggregation.nodeTypePolicy = NodeTypePolicy.SEPARATE_AT_LEAVES