The LayoutGraph API - Part 1: Structure
The yFiles graph structure implementation adheres to the idea that the graph should be the only instance in charge of all structural changes. (Structural changes most notably means node and edge creation and removal.) This paradigm has some important implications:
- There must exist a valid instance of type Graph to create any graph elements (“inside” this graph instance) at all.
- There is no way to create a node or an edge “outside” a graph.
- All created graph elements instantly belong to a distinct graph.
Additionally, there is a clear cascade of responsibilities for providing access to certain graph element information:
- A graph provides access to its nodes and edges.
- A node provides access to its edges; this can be all edges, or all incoming and outgoing edges, respectively.
- An edge provides access to its source and target node.
A graph can have an arbitrary number of nodes and edges, every node and edge, though, has exactly one graph. A node can have an arbitrary number of edges, but an edge always has two nodes (its source node and its target node).
Every instance of type Node and type Edge holds a reference to the graph instance it belongs to. This reference is cleared when the graph element has been removed or hidden from its graph. Furthermore, every graph element knows the position it has in the respective set of elements within its graph.
Class Graph offers access to its graph elements in several different ways. It returns enumerators and cursors to iterate over the respective sets of graph elements, or creates arrays containing references to all nodes or all edges from the graph. As an additional convenience, there are properties to get the first, respectively last element of any of the two sets.
const graph = getMyGraph()
// get the first and last node of the node set from the graph.
const firstNode = graph.firstNode
const lastNode = graph.lastNode
// Exchange first and last node of the node set.
graph.moveToLast(firstNode)
graph.moveToFirst(lastNode)
// get the first and last edge of the edge set from the graph.
const firstEdge = graph.firstEdge
const lastEdge = graph.lastEdge
// Exchange first and last edge of the edge set.
graph.moveToLast(firstEdge)
graph.moveToFirst(lastEdge)
// get an enumerable of all nodes from the graph.
const ne = graph.nodes
// get an enumerable of all edges from the graph.
const ee = graph.edges
// get a cursor of all nodes from the graph.
const nc = graph.getNodeCursor()
// get a cursor of all edges from the graph.
const ec = graph.getEdgeCursor()
// get an array of all nodes from the graph.
const nodes = graph.getNodeArray()
// get an array of all edges from the graph.
const edges = graph.getEdgeArray()
const graph: Graph = getMyGraph()
// get the first and last node of the node set from the graph.
const firstNode = graph.firstNode!
const lastNode = graph.lastNode!
// Exchange first and last node of the node set.
graph.moveToLast(firstNode)
graph.moveToFirst(lastNode)
// get the first and last edge of the edge set from the graph.
const firstEdge = graph.firstEdge!
const lastEdge = graph.lastEdge!
// Exchange first and last edge of the edge set.
graph.moveToLast(firstEdge)
graph.moveToFirst(lastEdge)
// get an enumerable of all nodes from the graph.
const ne = graph.nodes
// get an enumerable of all edges from the graph.
const ee = graph.edges
// get a cursor of all nodes from the graph.
const nc = graph.getNodeCursor()
// get a cursor of all edges from the graph.
const ec = graph.getEdgeCursor()
// get an array of all nodes from the graph.
const nodes = graph.getNodeArray()
// get an array of all edges from the graph.
const edges = graph.getEdgeArray()
While the returned cursors by definition have read-only behavior on the underlying container, the returned arrays actually are copies of the respective sets of elements from the graph at a certain point in time. In effect, this means that, for example, a returned node array can be modified in any way, i.e., nodes might be removed from the array or the sequence of nodes might be changed, without affecting the node set from the graph.
To change the sequence of any of the graph element sets class Graph has methods to move an element to the first or last position, respectively.
See also Collections and Iteration Mechanisms for more details.
Creating and Removing Graph Elements
When populating an existing graph with graph elements, it is important to observe certain preconditions:
- Only class Graph provides methods to create nodes and edges.
- To create an edge in a graph G it is necessary that both its source node and its target node already exist in G.
const graph = new Graph()
// create 2 nodes
const n1 = graph.createNode()
const n2 = graph.createNode()
// create an edge between the 2 nodes
const e = graph.createEdge(n1, n2)
const graph: Graph = new Graph()
// create 2 nodes
const n1 = graph.createNode()
const n2 = graph.createNode()
// create an edge between the 2 nodes
const e = graph.createEdge(n1, n2)
In addition to the most frequently used simple edge creation, it is also possible to specify the exact place where a newly created edge should be inserted into both the sequence of outgoing edges at its source node and the sequence of incoming edges at its target node. Furthermore, an already existing edge can be completely remodeled, i.e., both its end nodes as well as the insertion places at either end node can be changed. Reversing an edge, as another variant of changing an edge, is also supported.
Exact edge insertion shows the respective line of code for specifying the exact place of edge insertion.
const graph = getMyGraph()
const source = getMySourceNode()
const target = getMyTargetNode()
// Create a new edge at the second position of all incoming edges at the target
// node.
graph.createEdge(
source,
source.firstOutEdge,
target,
target.firstInEdge,
GraphElementInsertion.AFTER,
GraphElementInsertion.AFTER
)
const graph: Graph = getMyGraph()
const source = getMySourceNode()
const target = getMyTargetNode()
// Create a new edge at the second position of all incoming edges at the target
// node.
graph.createEdge(
source,
source.firstOutEdge,
target,
target.firstInEdge,
GraphElementInsertion.AFTER,
GraphElementInsertion.AFTER
)
The opposite operation to graph element creation is their removal. Class Graph offers methods to remove all graph elements at once, or to remove only a single node or a single edge. When removing either an instance of type Node or an instance of type Edge their reference to the containing graph is cleared.
const graph = getMyGraph()
// Remove single graph elements from the graph.
// Note that all edges adjacent to the given node are removed prior to the node
// itself.
graph.removeNode(graph.firstNode)
graph.removeEdge(graph.lastEdge)
// Remove all graph elements from the graph at once.
graph.clear()
const graph: Graph = getMyGraph()
// Remove single graph elements from the graph.
// Note that all edges adjacent to the given node are removed prior to the node
// itself.
graph.removeNode(graph.firstNode!)
graph.removeEdge(graph.lastEdge!)
// Remove all graph elements from the graph at once.
graph.clear()
When removing a single node from a graph, all its connecting edges are also removed. Technically, they are even removed before the node is, since an edge requires both its source node and target node to reside in the same graph.
An alternative to removing graph elements is to hide them. Hiding is a technique to only temporarily remove graph elements, i.e., taking them away from the graph structure to perform some task on the remaining graph, and thereafter putting them back into again, un-hiding them. Note that both removing and hiding a graph element only takes them away from the graph, the objects themselves still exist.
const graph = getMyGraph()
// Hide single graph elements from the graph.
// Note that all edges adjacent to 'exampleNode' are hidden prior to the node
// itself.
const exampleNode = graph.firstNode
graph.hide(exampleNode)
// Unhide single graph elements from the graph.
// Note that *only* 'exampleNode' is unhidden, while its formerly adjacent edges
// are not.
graph.unhide(exampleNode)
const graph: Graph = getMyGraph()
// Hide single graph elements from the graph.
// Note that all edges adjacent to 'exampleNode' are hidden prior to the node
// itself.
const exampleNode = graph.firstNode!
graph.hide(exampleNode)
// Unhide single graph elements from the graph.
// Note that *only* 'exampleNode' is unhidden, while its formerly adjacent edges
// are not.
graph.unhide(exampleNode)
In order to be able to unhide previously hidden graph elements, it is necessary to retain them, for example, in a data structure. It is recommended to use the specialized classes for hiding of graph elements. These classes automatically keep track of all hidden elements. They are described in Hiding Graph Elements.
Hiding a graph element only differs from removing a graph element in that there is no graph event fired that signals the structural change. As a consequence, any listeners to such graph events won’t be notified when either node or edge is hidden, which can easily result in data structures getting out of sync with the actual structure of the graph.
In addition to the number of nodes and the number of edges an instance of type Graph also knows whether a single graph element belongs to it or if there is an edge connecting two nodes. The latter feature is especially useful if there is no reference of an edge at hand, for instance.
const graph = getMyGraph()
// get the number of nodes in the graph.
// (Both methods are equivalent.)
const nodeCount = graph.nodeCount
const N = graph.n
// get the number of edges in the graph.
// (Both methods are equivalent.)
const edgeCount = graph.edgeCount
const E = graph.e
// Check if the graph is empty.
const isEmpty = graph.empty
// Check if the first node belongs to the graph.
const containsNode = graph.contains(graph.firstNode)
// Check if there is an edge between first and last node of the graph.
const containsEdge = graph.containsEdge(graph.firstNode, graph.lastNode)
const graph: Graph = getMyGraph()
// get the number of nodes in the graph.
// (Both methods are equivalent.)
const nodeCount = graph.nodeCount
const N = graph.n
// get the number of edges in the graph.
// (Both methods are equivalent.)
const edgeCount = graph.edgeCount
const E = graph.e
// Check if the graph is empty.
const isEmpty = graph.empty
// Check if the first node belongs to the graph.
const containsNode = graph.contains(graph.firstNode!)
// Check if there is an edge between first and last node of the graph.
const containsEdge = graph.containsEdge(graph.firstNode!, graph.lastNode!)
A graph element which has been hidden does not belong to any graph until it is unhidden again.
Class Node
Class Node is responsible for everything that is related to its connecting edges.
More specifically, an instance of type Node knows the overall number of connecting edges (the so-called degree of the node) as well as the division into the number of incoming edges (in-degree) and the number outgoing edges (out-degree).
const node = getMyNode()
// get the number of edges at a node.
const degree = node.degree
// get the number of incoming edges at a node.
const inDegree = node.inDegree
// get the number of outgoing edges at a node.
const outDegree = node.outDegree
A node also provides methods to easily test whether there is a connecting edge to another node.
const graph = getMyGraph()
const firstNode = graph.firstNode
const lastNode = graph.lastNode
// Check whether there is an edge between first and last node of the graph.
// First check if there is a connecting edge outgoing to 'lastNode'.
let e = firstNode.getEdgeTo(lastNode)
// If not, then check if there is a connecting edge incoming from 'lastNode'.
if (e === null) {
e = firstNode.getEdgeFrom(lastNode)
}
const graph: Graph = getMyGraph()
const firstNode = graph.firstNode!
const lastNode = graph.lastNode!
// Check whether there is an edge between first and last node of the graph.
// First check if there is a connecting edge outgoing to 'lastNode'.
let e: Edge | null = firstNode.getEdgeTo(lastNode)
// If not, then check if there is a connecting edge incoming from 'lastNode'.
if (e === null) {
e = firstNode.getEdgeFrom(lastNode)
}
Furthermore, it can give enumerators and cursors to iterate over all connecting edges, iterate over all incoming edges, and iterate over all outgoing edges. When iterating over all edges incoming edges appear first, outgoing edges last.
const node = getMyNode()
// get an enumerator to iterate over all edges at a node.
const edges = node.edges
// enumerate all edges using es-5 syntax
edges.forEach(console.log, console)
// get an enumerator to iterate over all incoming edges at a node.
const inEdges = node.inEdges
// enumerate all edges using es-6 for-of
for (const inEdge of inEdges) {
console.log(inEdge)
}
// get an enumerator to iterate over all outgoing edges at a node.
const outEdges = node.outEdges
// get a cursor to iterate over all edges at a node.
const edgeCursor = node.getEdgeCursor()
// get a cursor to iterate over all incoming edges at a node.
const inEdgeCursor = node.getInEdgeCursor()
// get a cursor to iterate over all outgoing edges at a node.
const outEdgeCursor = node.getOutEdgeCursor()
const node: YNode = getMyNode()
// get an enumerator to iterate over all edges at a node.
const edges = node.edges
// enumerate all edges using es-5 syntax
edges.forEach(console.log, console)
// get an enumerator to iterate over all incoming edges at a node.
const inEdges = node.inEdges
// enumerate all edges using es-6 for-of
for (const inEdge of inEdges) {
console.log(inEdge)
}
// get an enumerator to iterate over all outgoing edges at a node.
const outEdges = node.outEdges
// get a cursor to iterate over all edges at a node.
const edgeCursor = node.getEdgeCursor()
// get a cursor to iterate over all incoming edges at a node.
const inEdgeCursor = node.getInEdgeCursor()
// get a cursor to iterate over all outgoing edges at a node.
const outEdgeCursor = node.getOutEdgeCursor()
Since a self-loop is both an incoming and an outgoing edge at its node, it appears twice when iterating over all edges of the node. Also, a self-loop counts twice when asking for the degree of a node.
As a convenience, class Node furthermore provides enumerators and cursors to iterate over all its neighbors, to iterate over all its predecessors, or to iterate over all its successors. Predecessors and successors mean the nodes at the opposite of an incoming edge, and an outgoing edge, respectively.
const node = getMyNode()
// get an enumerator to iterate over all neighbor nodes.
const neighbors = node.neighbors
// get an enumerator to iterate over the source nodes of all incoming edges.
// These nodes are called predecessors.
const predecessors = node.predecessors
// get an enumerator to iterate over the target nodes of all outgoing edges.
// These nodes are called successors.
const successors = node.successors
// get a cursor to iterate over all neighbor nodes.
const neighborCursor = node.getNeighborCursor()
// get a cursor to iterate over the source nodes of all incoming edges.
// These nodes are called predecessors.
const predecessorCursor = node.getPredecessorCursor()
// get a cursor to iterate over the target nodes of all outgoing edges.
// These nodes are called successors.
const successorCursor = node.getSuccessorCursor()
const node: YNode = getMyNode()
// get an enumerator to iterate over all neighbor nodes.
const neighbors = node.neighbors
// get an enumerator to iterate over the source nodes of all incoming edges.
// These nodes are called predecessors.
const predecessors = node.predecessors
// get an enumerator to iterate over the target nodes of all outgoing edges.
// These nodes are called successors.
const successors = node.successors
// get a cursor to iterate over all neighbor nodes.
const neighborCursor = node.getNeighborCursor()
// get a cursor to iterate over the source nodes of all incoming edges.
// These nodes are called predecessors.
const predecessorCursor = node.getPredecessorCursor()
// get a cursor to iterate over the target nodes of all outgoing edges.
// These nodes are called successors.
const successorCursor = node.getSuccessorCursor()
Class Edge
The most important information an instance of type Edge provides is its source node and its target node. Closely related is the method to get the opposite when holding one of the edge’s end nodes.
const edge = getMyEdge()
// get the two end nodes of an edge.
const source = edge.source
const target = edge.target
// getting the opposite when holding one of either source or target node.
const opposite = edge.opposite(source)
const edge: Edge = getMyEdge()
// get the two end nodes of an edge.
const source = edge.source
const target = edge.target
// getting the opposite when holding one of either source or target node.
const opposite = edge.opposite(source)
Although a hidden edge holds no reference to a graph, it can still provide access to its source and target node, independent of their status.
As a convenience, class Edge's property selfLoop] additionally offers information whether the edge is a self-loop.
Ignoring the directedness of the yFiles algorithms graph structure implementation and instead interpreting it undirected would be done using the neighbors property, respectively method getNeighborCursor of class Node, or a combination of property edges, respectively method getEdgeCursor of class Node and method opposite of class Edge.
Group Nodes
As described in The Graph Model, yFiles for HTML provides an enhanced graph model with support for group nodes. In this model a node can be in another node, its parent group, and each group can contain an arbitrary number of nodes, its children.
A layout style that is suitable for group nodes typically places children of the same group near each other and have their parent enclosing them.
If an IGraph contains groups, applying a layout automatically creates a corresponding layout graph model with grouping information. Group node insets and minimum size constraints are automatically configured, too.
LayoutGraph and Graph have no intrinsic support for group nodes. Instead, a couple of dedicated data provider keys defined in class GroupingKeys must be registered with the graph to specify the information about the grouped graph’s hierarchy of nodes for automatic layout and graph analysis.
Layout preparation demonstrates how to set up a grouped graph by filling the corresponding data providers and registering them with the graph using the data provider look-up keys defined in class GroupingKeys.
const graph = getMyLayoutGraph()
// Create the node maps that are to be used as data providers later on.
const groupKey = graph.createNodeMap()
const nodeID = graph.createNodeMap()
const parentNodeID = graph.createNodeMap()
// Register the node maps as data providers with the graph.
// Use the "well-known" look-up keys defined in class GroupingKeys.
graph.addDataProvider(GroupingKeys.GROUP_DP_KEY, groupKey)
graph.addDataProvider(GroupingKeys.NODE_ID_DP_KEY, nodeID)
graph.addDataProvider(GroupingKeys.PARENT_NODE_ID_DP_KEY, parentNodeID)
// Now, set up the hierarchy of nodes of the grouped graph, i.e., define some
// of the nodes to be group nodes and others to be their content.
mySetupNodeHierarchy(graph, groupKey, nodeID, parentNodeID)
// Invoke the layout algorithm.
invokeLayout(graph, new HierarchicLayout(), false)
const graph: LayoutGraph = getMyLayoutGraph()
// Create the node maps that are to be used as data providers later on.
const groupKey = graph.createNodeMap()
const nodeID = graph.createNodeMap()
const parentNodeID = graph.createNodeMap()
// Register the node maps as data providers with the graph.
// Use the "well-known" look-up keys defined in class GroupingKeys.
graph.addDataProvider(GroupingKeys.GROUP_DP_KEY, groupKey)
graph.addDataProvider(GroupingKeys.NODE_ID_DP_KEY, nodeID)
graph.addDataProvider(GroupingKeys.PARENT_NODE_ID_DP_KEY, parentNodeID)
// Now, set up the hierarchy of nodes of the grouped graph, i.e., define some
// of the nodes to be group nodes and others to be their content.
mySetupNodeHierarchy(graph, groupKey, nodeID, parentNodeID)
// Invoke the layout algorithm.
invokeLayout(graph, new HierarchicLayout(), false)
The information for the node IDs and the parent node IDs is of symbolic nature that is used in the process of layout calculation to identify the proper parent for a given child, but also to find all children that belong to the same parent. Hence, it is important for the symbolic IDs to properly match between these two data providers, so that the grouped graph’s hierarchy of nodes is correctly expressed.
Encoding a grouped graph’s hierarchy of nodes in data providers demonstrates possible content for the data providers. Here, the nodes themselves are used to denote symbolic IDs for both “ordinary” nodes and group nodes. Carefully observe the usage of the indirection scheme in this example for setting up the parent-child relation.
// First, define node IDs for all nodes
for (let i = 0; i < n.length; i++) {
// Set a symbolic ID for the node that is used for look-up purposes.
nodeID.set(n[i], n[i])
}
// Now, set up the hierarchy of nodes of the grouped graph, i.e., define some
// of the nodes to be group nodes and others to be their content.
// First, define nodes 1, 5, and 9 to be group nodes
groupKey.setBoolean(n[1], true)
groupKey.setBoolean(n[5], true)
groupKey.setBoolean(n[9], true)
// Node 2 and 3 are defined child of node 1;
parentNodeID.set(n[2], n[1])
parentNodeID.set(n[3], n[1])
// Node 6 and 7 are defined child of node 5.
parentNodeID.set(n[6], n[5])
parentNodeID.set(n[7], n[5])
// Nodes 0, 4, and 8 remain "ordinary" nodes...
A group node’s size is determined by the bounding box that encloses its children and additional insets that are added to each of the box’s side. To specify insets individually, a data provider can be used to hold an Insets object for each group node. This data provider is then registered with the graph using the look-up key GROUP_NODE_INSETS_DP_KEY defined in class GroupingKeys.
Defining a group node’s insets shows how to add individual Insets objects for group nodes to a node map, and how the node map is registered as a data provider with the graph.
const graph = getMyLayoutGraph()
// Create the node map that is to be used as a data provider later on.
const groupNodeInsets = graph.createNodeMap()
// Predefine some Insets objects.
const insets = new Array(3)
insets[0] = new Insets(10, 20, 30, 40)
insets[1] = new Insets(20, 20, 20, 20)
insets[2] = new Insets(40, 30, 20, 10)
const groupNodes = getListOfAllGroupNodes(graph)
groupNodes.forEach((n) => groupNodeInsets.set(n, insets[getGroupType(n)]))
// Register the node map as a data provider with the graph.
// Use the "well-known" look-up keys defined in class GroupingKeys.
graph.addDataProvider(GroupingKeys.GROUP_NODE_INSETS_DP_KEY, groupNodeInsets)
// Invoke the layout algorithm.
invokeLayout(graph, new HierarchicLayout(), false)
const graph: LayoutGraph = getMyLayoutGraph()
// Create the node map that is to be used as a data provider later on.
const groupNodeInsets = graph.createNodeMap()
// Predefine some Insets objects.
const insets = new Array(3)
insets[0] = new Insets(10, 20, 30, 40)
insets[1] = new Insets(20, 20, 20, 20)
insets[2] = new Insets(40, 30, 20, 10)
const groupNodes = getListOfAllGroupNodes(graph)
groupNodes.forEach((n) => groupNodeInsets.set(n, insets[getGroupType(n)]))
// Register the node map as a data provider with the graph.
// Use the "well-known" look-up keys defined in class GroupingKeys.
graph.addDataProvider(GroupingKeys.GROUP_NODE_INSETS_DP_KEY, groupNodeInsets)
// Invoke the layout algorithm.
invokeLayout(graph, new HierarchicLayout(), false)
Class FixGroupLayoutStage adds support for the fixed group node policy to both hierarchical layout and orthogonal layout. Setup for fixed group node content shows how the fixed group node policy is realized as a layout stage that is prepended to the actual layout algorithm’s invocation.
/**
* @param {!LayoutGraph} graph
* @param {!MultiStageLayout} layout
* @param {boolean} orthogonal
*/
function invokeLayout(graph, layout, orthogonal) {
// Create a specialized layout stage that fixes the contents of the group
// nodes.
const fixedGroupLayoutStage = new FixGroupLayoutStage()
if (orthogonal) {
fixedGroupLayoutStage.interEdgeRoutingStyle = InterEdgeRoutingStyle.ORTHOGONAL
}
// Prepend the stage to the given layout algorithm.
layout.prependStage(fixedGroupLayoutStage)
// Invoke buffered layout for the given layout algorithm.
new BufferedLayout(layout).applyLayout(graph)
// Remove the prepended layout stage.
layout.removeStage(fixedGroupLayoutStage)
}function invokeLayout(graph: LayoutGraph, layout: MultiStageLayout, orthogonal: boolean): void {
// Create a specialized layout stage that fixes the contents of the group
// nodes.
const fixedGroupLayoutStage = new FixGroupLayoutStage()
if (orthogonal) {
fixedGroupLayoutStage.interEdgeRoutingStyle = InterEdgeRoutingStyle.ORTHOGONAL
}
// Prepend the stage to the given layout algorithm.
layout.prependStage(fixedGroupLayoutStage)
// Invoke buffered layout for the given layout algorithm.
new BufferedLayout(layout).applyLayout(graph)
// Remove the prepended layout stage.
layout.removeStage(fixedGroupLayoutStage)
}Hiding Graph Elements
This section describes features of the graph model of the layout part of yFiles. You’ll have to work with this model only if you implement your own ILayoutAlgorithm, ILayoutStage, or another type from the layout part. The section Applying an Automatic Layout describes how to apply an automatic layout to an IGraph or GraphComponent.
Support for hiding graph elements is further completed by classes LayoutGraphHider and GraphPartitionManager. In addition to the methods from class Graph, GraphHider offers various methods to hide arbitrary collections of graph elements or even all elements from the graph at once. Moreover, it automatically keeps track of all elements hidden as a result of such method calls.
To unhide graph elements, the LayoutGraphHider class provides a small set of methods that collectively employ all-at-once behavior when unhiding, i.e., all elements previously hidden are unhidden at once.
const edgesToHide = graph.getDataProvider('EdgesToHide')
// Hide all edges for which the data provider returns true
const graphHider = new LayoutGraphHider(graph)
// NOTE: we cannot use an edge cursor since hiding the edges will
// modify the underlying collection. Therefore we use GetEdgeArray()
for (const edge of graph.getEdgeArray()) {
if (edgesToHide.getBoolean(edge)) {
graphHider.hide(edge)
}
}
// now do something with the graph
layoutAlgorithm.applyLayout(graph)
// cleanup
graphHider.unhideAll()
const edgesToHide = graph.getDataProvider('EdgesToHide')!
// Hide all edges for which the data provider returns true
const graphHider = new LayoutGraphHider(graph)
// NOTE: we cannot use an edge cursor since hiding the edges will
// modify the underlying collection. Therefore we use GetEdgeArray()
for (const edge of graph.getEdgeArray()) {
if (edgesToHide.getBoolean(edge)) {
graphHider.hide(edge)
}
}
// now do something with the graph
layoutAlgorithm.applyLayout(graph)
// cleanup
graphHider.unhideAll()
The GraphPartitionManager class extends the idea from LayoutGraphHider in a way so that it is possible to mark parts of the graph as so-called partitions and hide/unhide these.
When working with graph hierarchies, graph elements must not be hidden but instead should be removed.
Iteration Mechanisms
The yFiles cursor hierarchy with interface ICursor and its typed sub-interfaces INodeCursor and IEdgeCursor provides bidirectional iteration over a sequence of objects in a uniform fashion.
A cursor offers access to the object it currently points to, it tells whether the current position is valid or “out of range,” and finally a cursor gives the size of the sequence it iterates over. Upon creation, a cursor by default points to the first object of the underlying sequence. Moving the cursor position is possible both absolutely, i.e., to the first or last object of the sequence and relatively, i.e., to the next or the previous object. Note that the typing of the sub-interfaces takes place at the access methods, i.e., these return references of type Node and Edge, respectively.
const graph = getMyGraph()
// get a cursor to iterate over all edges from the edge set of the graph.
const ec = graph.getEdgeCursor()
// Ask for the size of the underlying sequence of edges.
const size = ec.size
// Move the cursor to the last position.
ec.toLast()
const graph: Graph = getMyGraph()
// get a cursor to iterate over all edges from the edge set of the graph.
const ec = graph.getEdgeCursor()
// Ask for the size of the underlying sequence of edges.
const size = ec.size
// Move the cursor to the last position.
ec.toLast()
A cursor cannot change the sequence it iterates over, particularly, it cannot remove elements from the underlying container. So effectively, a cursor constitutes a read-only view on the sequence it iterates over. To actually remove an element from the underlying container, the container itself must be accessible.
The most prominent yFiles types that provide cursors to iterate over object, node, or edge sequences are YList, NodeList, EdgeList, Graph, and Node.
Forward iteration with various cursor types and Backward iteration show the usage of cursors in conjunction with loops to iterate over a sequence of either typed or untyped objects. Note the additional cursor movement to the last position of the sequence with backward iteration.
const graph = getMyGraph()
const list = getMyYList()
// Forward iterate over all objects from the list.
for (const c = list.cursor(); c.ok; c.next()) {
const obj = c.current
}
// Forward iterate over all nodes of the node set from the graph.
for (const nc = graph.getNodeCursor(); nc.ok; nc.next()) {
const n = nc.node
}
// Forward iterate over all edges from the edge set of the graph.
for (const ec = graph.getEdgeCursor(); ec.ok; ec.next()) {
const e = ec.edge
}
const graph: Graph = getMyGraph()
const list: YList = getMyYList()
// Forward iterate over all objects from the list.
for (const c = list.cursor(); c.ok; c.next()) {
const obj = c.current
}
// Forward iterate over all nodes of the node set from the graph.
for (const nc = graph.getNodeCursor(); nc.ok; nc.next()) {
const n = nc.node
}
// Forward iterate over all edges from the edge set of the graph.
for (const ec = graph.getEdgeCursor(); ec.ok; ec.next()) {
const e = ec.edge
}
// get a cursor to iterate over the list.
const c = list.cursor()
// Move the cursor to the last position of the sequence.
// Backward iterate over all objects.
for (c.toLast(); c.ok; c.prev()) {
const obj = c.current
}
Interface ICursor does not provide a method to remove an element from an underlying container. Instead, any elements must be removed from the container itself.
const graph = getMyGraph()
// Remove unwanted nodes from the node set of the graph.
for (const nc = graph.getNodeCursor(); nc.ok; nc.next()) {
if (isUnwanted(nc.node)) {
// The graph is asked to remove the specified node.
graph.removeNode(nc.node)
}
}
const graph: Graph = getMyGraph()
// Remove unwanted nodes from the node set of the graph.
for (const nc = graph.getNodeCursor(); nc.ok; nc.next()) {
if (isUnwanted(nc.node)) {
// The graph is asked to remove the specified node.
graph.removeNode(nc.node!)
}
}
However, when an element that is pointed to by a cursor gets removed from the underlying container, the cursor does not change state, i.e., it still points to the same, now removed, element. Moving the cursor thereafter either forward or backward has the same effect as if the element was in the container, i.e., the cursor subsequently points to the next, respectively previous element from the foregoing sequence.
Once the cursor has been moved away from the removed element’s position, though, there is no way to return to that position again. In conclusion, a simple call sequence as in Call sequence to move a cursor does not necessarily return the cursor to the originating position in the sequence.
const graph = getMyGraph()
const nc = graph.getNodeCursor()
// The cursor points to the first position of the sequence, i.e., to the first
// node of the node set.
let firstN = nc.node
nc.next() // Cursor now points to the second node.
let nextN = nc.node
// The simple call sequence: move forward and immediately backward.
nc.next() // Cursor now points to the third node.
nc.prev() // Cursor now points to the second node.
// Test for consistency.
if (nextN !== nc.node) {
throw new Error('Inconsistent cursor.')
}
// Move the cursor back to the first node.
nc.toFirst()
firstN = nc.node
nc.next() // Cursor now points to the second node.
nextN = nc.node
// Now, remove the second node from the node set.
graph.removeNode(nc.node)
// The simple call sequence: move forward and immediately backward.
nc.next() // Cursor now points to the third node.
nc.prev() // Cursor now points to the first node.
// Test for consistency.
if (nextN !== nc.node) {
throw new Error('Inconsistent cursor.')
// This time an exception will be thrown that the cursor has become
// inconsistent.
}
const graph: Graph = getMyGraph()
const nc = graph.getNodeCursor()
// The cursor points to the first position of the sequence, i.e., to the first
// node of the node set.
let firstN = nc.node
nc.next() // Cursor now points to the second node.
let nextN = nc.node
// The simple call sequence: move forward and immediately backward.
nc.next() // Cursor now points to the third node.
nc.prev() // Cursor now points to the second node.
// Test for consistency.
if (nextN !== nc.node) {
throw new Error('Inconsistent cursor.')
}
// Move the cursor back to the first node.
nc.toFirst()
firstN = nc.node
nc.next() // Cursor now points to the second node.
nextN = nc.node
// Now, remove the second node from the node set.
graph.removeNode(nc.node!)
// The simple call sequence: move forward and immediately backward.
nc.next() // Cursor now points to the third node.
nc.prev() // Cursor now points to the first node.
// Test for consistency.
if (nextN !== nc.node) {
throw new Error('Inconsistent cursor.')
// This time an exception will be thrown that the cursor has become
// inconsistent.
}
Additionally to iteration using cursors, there is another possibility to specifically iterate over the edges adjacent to a node. Non-cursor iteration over a node’s edges demonstrates this technique.
const node = getMyNode()
// Retrieve the initial incoming edge from the node.
let e = node.firstInEdge
while (e !== null) {
// Successively retrieve the next incoming edge.
e = e.nextInEdge
}
// Retrieve the initial outgoing edge from the node.
e = node.firstOutEdge
while (e !== null) {
// Successively retrieve the next outgoing edge.
e = e.nextOutEdge
}
const node: YNode = getMyNode()
// Retrieve the initial incoming edge from the node.
let e: Edge | null = node.firstInEdge
while (e !== null) {
// Successively retrieve the next incoming edge.
e = e.nextInEdge
}
// Retrieve the initial outgoing edge from the node.
e = node.firstOutEdge
while (e !== null) {
// Successively retrieve the next outgoing edge.
e = e.nextOutEdge
}
Collections
Classes NodeList and EdgeList, the typed descendants of class YList, are the most frequently encountered yFiles data structures to store graph elements.
Common to all lists is their support for the methods from interface ICollection<T> via the implementation in class YList. Beyond this implementation, class YList provides advanced list access and manipulation services which strongly rely on the possibilities offered by class ListCell.
High-level features
In addition to the methods from interface ICollection there are several further methods offered. For instance, it is possible to add elements explicitly to the front or the back of a list. Also, removing elements from the list is possible from both the front and the back. Note that the method names for removing elements from either end of the list resemble those of abstract data type stack.
Other methods offer list sorting, reversing a list, or the splicing of two lists into one.
const list = getMyYList()
// Add new elements to either end of the list.
list.addFirst('I am the first node!')
list.addLast('I am the last node!')
// Remove elements from either end of the list.
list.removeCell(list.firstCell)
list.removeCell(list.lastCell)
const list: YList = getMyYList()
// Add new elements to either end of the list.
list.addFirst('I am the first node!')
list.addLast('I am the last node!')
// Remove elements from either end of the list.
list.removeCell(list.firstCell!)
list.removeCell(list.lastCell!)
To iterate over the elements of the list it provides an enumerator and an ICursor (respectively INodeCursor and IEdgeCursor with classes NodeList and EdgeList). See also the discussion in Iteration Mechanisms.
Efficiently removing elements from a list using a cursor shows how to efficiently remove an element from a list using a cursor. The cursor directly points to the element, there is no need to search the list.
const list = getMyYList()
// Remove unwanted objects from the list.
for (const c = list.cursor(); c.ok; c.next()) {
if (isUnwanted(c.current)) {
list.removeAtCursor(c)
}
}
const list: YList = getMyYList()
// Remove unwanted objects from the list.
for (const c = list.cursor(); c.ok; c.next()) {
if (isUnwanted(c.current)) {
list.removeAtCursor(c)
}
}
Low-level features
Class ListCell is the building block of the doubly linked list structure. It knows both its predecessor and its successor, and provides read/write behavior for the actual data it is holding.
const list = getMyYList()
// get the first cell of the list.
const firstCell = list.firstCell
// get the actual data the cell is holding.
const obj = firstCell.info
// Change the actual data.
firstCell.info = 'Updated Data.'
const list: YList = getMyYList()
// get the first cell of the list.
const firstCell = list.firstCell!
// get the actual data the cell is holding.
const obj = firstCell.info
// Change the actual data.
firstCell.info = 'Updated Data.'
Using an instance of type ListCell, for example, it is possible to have fast access to the preceding, respectively succeeding cell from the containing list, or to insert new cells relatively to already contained ones. By way of the successors (predecessors) of a ListCell instance, direct iteration over the elements of a list is possible.
const list = getMyYList()
// Directly (backward) iterate over the list.
for (let lc = list.lastCell; lc !== null; lc = list.predCell(lc)) {
if (conditionIsSatisfied(lc.info)) {
// Insert a new cell with given data relatively to the held reference cell.
// The newly allocated cell will be returned.
const newCell = list.insertBefore('Prepended Data.', lc)
}
}
const list: YList = getMyYList()
// Directly (backward) iterate over the list.
for (let lc: ListCell | null = list.lastCell; lc !== null; lc = list.predCell(lc)) {
if (conditionIsSatisfied(lc.info)) {
// Insert a new cell with given data relatively to the held reference cell.
// The newly allocated cell will be returned.
const newCell = list.insertBefore('Prepended Data.', lc)
}
}
Binding Data to Graph Elements
This section describes features of the graph model of the layout part of yFiles. You’ll have to work with this model only if you implement your own ILayoutAlgorithm, ILayoutStage, or another type from the layout part. The section Applying an Automatic Layout describes how to apply an automatic layout to an IGraph or GraphComponent.
The concept of data accessors comprises two aspects which are commonly used in different scenarios. To bind supplemental data to graph elements that should be read-only, an implementation of interface IDataProvider suffices. We call these implementations data providers.
A data accessor with full read/write behavior, though, additionally implements interface IDataAcceptor. yFiles for HTML knows these implementations as maps, and has two dedicated interfaces already defined, INodeMap and IEdgeMap.
Both extend interface IDataMap which is a combination of interfaces IDataProvider and IDataAcceptor. Applying the two semantics it is, e.g., possible to restrict certain callees to “immutable” data, while others are allowed to make changes.
Observe that both interfaces INodeMap and IEdgeMap show identical signatures on their respective methods, using Object instead of either Node or Edge as the parameter type for their key. Actual implementations should nevertheless ensure that the keys provided have correct type.
The concept of data accessors gives a brief overview of the classes involved in the basic concepts of maps and data providers.
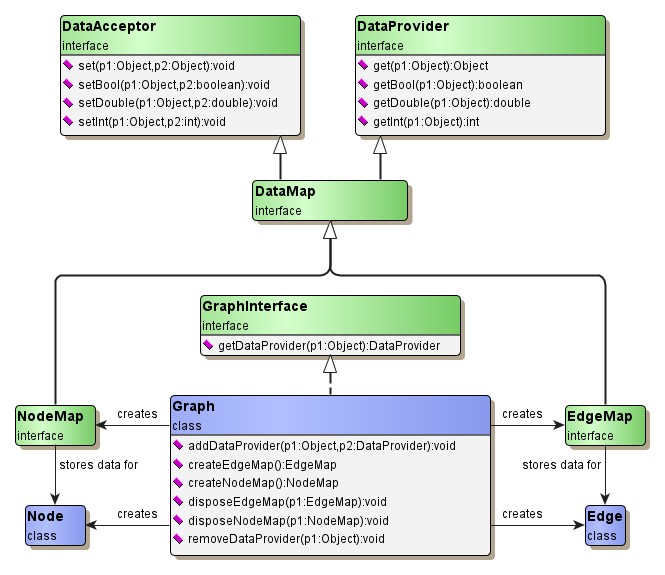
Maps and Data Providers
Common to all data accessor implementations which are offered by the yFiles library is that they cover all elements of a set, i.e., a node map provides values for all nodes from a graph (however, these may all be default values when there hasn’t been anything stored yet).
Storing and retrieving data associated with a node shows how node maps are used to store and retrieve arbitrary data.
const graph = getMyGraph()
const labelNodeMap = getMyNodeMap('labelNodeMap')
const counterNodeMap = getMyNodeMap('counterNodeMap')
// Bind a label to the first node of the node set.
// The bound data actually is of type string.
labelNodeMap.set(graph.firstNode, 'I am the first node!')
// Increase the value stored in 'counterNodeMap' for the last node.
// The bound data is an int.
counterNodeMap.setInt(graph.lastNode, counterNodeMap.getInt(graph.lastNode) + 1)
// Print out the label of the first node.
console.log('The name of the first node is: ')
console.log(labelNodeMap.get(graph.firstNode))
const graph: Graph = getMyGraph()
const labelNodeMap: INodeMap = getMyNodeMap('labelNodeMap')
const counterNodeMap: INodeMap = getMyNodeMap('counterNodeMap')
// Bind a label to the first node of the node set.
// The bound data actually is of type string.
labelNodeMap.set(graph.firstNode, 'I am the first node!')
// Increase the value stored in 'counterNodeMap' for the last node.
// The bound data is an int.
counterNodeMap.setInt(graph.lastNode, counterNodeMap.getInt(graph.lastNode) + 1)
// Print out the label of the first node.
console.log('The name of the first node is: ')
console.log(labelNodeMap.get(graph.firstNode))
Comparing map implementations lists the differences of some data accessor implementations.
| Domain | Memory | Performance | Note | |
|---|---|---|---|---|
Default Map Implementations
Although writing customized implementations for interfaces INodeMap or IEdgeMap is easy, the most frequently used way to get these is conveniently provided by class Graph. Creating default node maps shows one of the two methods that both return default implementations of these interfaces which can be used for most purposes and data types.
The maps returned by these methods hold exactly one value for a given key, i.e., no matter how many calls to any of the setter methods are issued for a given key, only the last value set will be held. Also, the type of the key given with a setter method is restricted to the respective type of graph elements, i.e., restricted to Node or Edge. The type of the value though, is not restricted to be same over the range of all nodes, for example. In fact, it would be perfectly legal to set a double value with one node, and boolean values with every other. This, however, is strongly discouraged, since it definitely leads to problems when the values will be retrieved.
Default map implementations can be created at any time, even when the graph is empty. From the moment of creation on, they will cover all graph elements from the respective set, as well as all respective elements created by the graph thereafter. However, these maps cannot cover elements that are hidden at the time of creation.
Note that these default implementations have to be properly disposed of after usage to release the allocated resources. To this end, class Graph has appropriate methods for either kind of default implementations.
const graph = getMyGraph()
// Obtain a new INodeMap default implementation from the graph.
const nodeMap = graph.createNodeMap()
// Set values for some of the nodes.
nodeMap.setNumber(graph.firstNode, 3.14)
nodeMap.setNumber(graph.lastNode, 42.0)
// Print the values stored in the node map.
graph.nodes.forEach((n) => {
console.log(`Node ${n}: ${nodeMap.getNumber(n)}`)
})
// Finally release the resources previously allocated by the createNodeMap()
// method.
graph.disposeNodeMap(nodeMap)
const graph: Graph = getMyGraph()
// Obtain a new INodeMap default implementation from the graph.
const nodeMap = graph.createNodeMap()
// Set values for some of the nodes.
nodeMap.setNumber(graph.firstNode, 3.14)
nodeMap.setNumber(graph.lastNode, 42.0)
// Print the values stored in the node map.
graph.nodes.forEach((n) => {
console.log(`Node ${n}: ${nodeMap.getNumber(n)}`)
})
// Finally release the resources previously allocated by the createNodeMap()
// method.
graph.disposeNodeMap(nodeMap)
Creating Customized Data Accessors
In addition to using the default map implementations provided by class Graph, there are further ways to create either maps or data providers. For example, data providers can be implemented so that the actual data is only implicitly defined, i.e., it is calculated on the fly when the value is asked for. This way, it is possible to “store” large amounts of data without having any memory be allocated. Using class DataProviderAdapter to create customized data providers demonstrates how to use class DataProviderAdapter to define a custom IDataProvider implementation.
// Define an IDataProvider implementation that for each node in the graph
// returns an int that is the square of the node's index.
class MyDataProvider extends DataProviderBase {
/**
* @param {*} dataHolder
* @returns {number}
*/
getInt(dataHolder) {
if (!(dataHolder instanceof YNode)) {
throw new Error('Key has wrong type.')
}
const node = dataHolder
return node.index * node.index
}
}
// Define an IDataProvider implementation that for each edge in the graph
// returns a distance value that is the difference of the values returned by
// the given IDataProvider for the source and target node.
class MyOtherDataProvider extends DataProviderBase {
/**
* @param {!IDataProvider} dp
*/
constructor(dp) {
super()
this.dp = dp
}
/**
* @param {*} dataHolder
* @returns {number}
*/
getInt(dataHolder) {
if (!(dataHolder instanceof Edge)) {
throw new Error('Key has wrong type.')
}
const edge = dataHolder
return this.dp.getInt(edge.target) - this.dp.getInt(edge.source)
}
}
/**
* @param {!Graph} graph
*/
function testDataProviders(graph) {
const edgeLengthProvider = new MyOtherDataProvider(new MyDataProvider())
// Display the values "stored" (i.e., calculated on the fly) for each edge.
graph.edges.forEach((e) => {
console.log(`Edge ${e}: ${edgeLengthProvider.getInt(e)}`)
})
}// Define an IDataProvider implementation that for each node in the graph
// returns an int that is the square of the node's index.
class MyDataProvider extends DataProviderBase {
getInt(dataHolder: any | null): number {
if (!(dataHolder instanceof YNode)) {
throw new Error('Key has wrong type.')
}
const node = dataHolder
return node.index * node.index
}
}
// Define an IDataProvider implementation that for each edge in the graph
// returns a distance value that is the difference of the values returned by
// the given IDataProvider for the source and target node.
class MyOtherDataProvider extends DataProviderBase {
constructor(private readonly dp: IDataProvider) {
super()
}
getInt(dataHolder: any | null): number {
if (!(dataHolder instanceof Edge)) {
throw new Error('Key has wrong type.')
}
const edge = dataHolder
return this.dp.getInt(edge.target) - this.dp.getInt(edge.source)
}
}
function testDataProviders(graph: Graph): void {
const edgeLengthProvider = new MyOtherDataProvider(new MyDataProvider())
// Display the values "stored" (i.e., calculated on the fly) for each edge.
graph.edges.forEach((e) => {
console.log(`Edge ${e}: ${edgeLengthProvider.getInt(e)}`)
})
}Class DataProviders offers a set of static methods to conveniently create several specialized data provider implementations for either nodes or edges. For instance, there are methods to create data providers from constant values, from given arrays, or from existing data providers.
Class Maps provides a set of static methods to conveniently create several specialized map implementations:
- The createNodeMap and createEdgeMap methods that take IMap<TKey,TValue> implementations and return either an INodeMap or an IEdgeMap view of the given instances. Basically, this allows for any valid IMap<TKey,TValue> implementation, e.g., IMap<TKey,TValue>, to be used in conjunction with the yFiles graph implementation.
- The various createIndexNodeMapForBoolean and createIndexEdgeMapForBoolean methods return map implementations that are fast and at the same time use little memory.
HashMap-backed map implementations
HashMap implementations are true multi-purpose data holders, there is no restriction to the type of the keys nor the type of the values. Particularly, the keys are not restricted to graph elements. Compared to the default implementations of interface INodeMap and IEdgeMap provided by class Graph they are generally a bit slower. However, their memory usage is proportional to the amount of the data that is actually associated with the entities.
Map implementations backed by an instance of type HashMap are especially suited for sparsely distributed data, i.e., only few entities of a domain have non-null data associated with them.
Index-based map implementations
Index-based map implementations are very fast and use only little memory, their drawback, however, is that once instantiated their values are restricted to the type given at creation time. More important though, all index-based containers require the respective set of graph elements to remain unaltered, i.e., there are no operations allowed that change the sequence of the graph elements in any way.
const graph = getMyGraph()
// Create an edge map that holds a boolean value for each edge from
// the edge set of the graph.
const map = Maps.createIndexEdgeMapForBoolean(new Array(graph.e))
// Store some data into the edge map.
// (For each edge the map will contain the boolean value indicating whether
// the edge points from a node with a lower index to a node with
// a higher index.)
graph.nodes.forEach((n) => {
n.edges.forEach((e) => {
map.setBoolean(e, e.source.index < e.target.index)
})
})
const graph: Graph = getMyGraph()
// Create an edge map that holds a boolean value for each edge from
// the edge set of the graph.
const map = Maps.createIndexEdgeMapForBoolean(new Array(graph.e))
// Store some data into the edge map.
// (For each edge the map will contain the boolean value indicating whether
// the edge points from a node with a lower index to a node with
// a higher index.)
graph.nodes.forEach((n) => {
n.edges.forEach((e) => {
map.setBoolean(e, e.source.index < e.target.index)
})
})
Notes on Data Accessors
Successfully using a data accessor requires a kind of “agreement” on the type the data accessor holds. More precisely, storing the value for a key and retrieving the value thereafter has to be done using setter and getter methods of matching type. The result when using setter/getter methods with non-matching types highly depends on the specific data accessor implementation. Successfully using data accessors demonstrates the proper usage of a data accessor.
This rule furthermore implies that a self-made data accessor has to provide the proper getter (and/or setter) methods when it is used as a parameter to an algorithm.
const graph = getMyGraph()
// get a default INodeMap implementation from the graph.
const nm = graph.createNodeMap()
// Store values for some chosen nodes.
nm.setBoolean(graph.firstNode, true)
nm.setBoolean(graph.lastNode, true)
// Retrieve the stored values.
// WRONG. WRONG. WRONG.
// Boolean values cannot be retrieved as ints.
const firstValue = nm.getInt(graph.firstNode)
const lastValue = nm.getInt(graph.lastNode)
// Retrieve the stored values.
// RIGHT.
const first = nm.getBoolean(graph.firstNode)
const last = nm.getBoolean(graph.lastNode)
const graph: Graph = getMyGraph()
// get a default INodeMap implementation from the graph.
const nm = graph.createNodeMap()
// Store values for some chosen nodes.
nm.setBoolean(graph.firstNode, true)
nm.setBoolean(graph.lastNode, true)
// Retrieve the stored values.
// WRONG. WRONG. WRONG.
// Boolean values cannot be retrieved as ints.
const firstValue = nm.getInt(graph.firstNode)
const lastValue = nm.getInt(graph.lastNode)
// Retrieve the stored values.
// RIGHT.
const first = nm.getBoolean(graph.firstNode)
const last = nm.getBoolean(graph.lastNode)
Binding Data to Elements of IGraph
Most layout algorithms can be configured with additional data. Internally, they are using data providers for this task. When applying a layout on an IGraph, there are different ways to provide the data.
The most recommended way is to use the corresponding LayoutData. For instance, HierarchicLayout can be configured using HierarchicLayoutData. Besides type safety and code completion, LayoutData has the advantage that it registers data providers on the internally used LayoutGraph while the original IGraph is not affected.
If one uses a custom layout stage, an instance of GenericLayoutData can be used. It provides the possibility of registering ItemCollection<TItem>s and ItemMapping<TItem,TValue>s with arbitrary data provider keys. Like the predefined LayoutData types, the GenericLayoutData leaves the original IGraph unaffected.
// an example data provider key for an ItemCollection:
// the corresponding provider returns true for each node which is contained in the collection
const IncludedNodesDpKey = new NodeDpKey(YBoolean.$class, ExampleStage.$class, 'IncludedNodesDpKey')
// an example data provider key for an ItemMapping:
// the corresponding provider returns a number for each edge
const EdgeWeightDpKey = new EdgeDpKey(YNumber.$class, ExampleStage.$class, 'EdgeWeightDpKey')
// generate generic data
const genericData = new GenericLayoutData()
// add an ItemCollection for IncludedNodesDpKey
const includedNodes = genericData.addNodeItemCollection(IncludedNodesDpKey)
includedNodes.delegate = (node) => 'IncludeMe' === node.tag
// add an ItemMapping for EdgeWeightDpKey
const edgeWeights = genericData.addEdgeItemMapping(EdgeWeightDpKey)
edgeWeights.mapper.set(edge1, 10)
edgeWeights.mapper.set(edge2, 20)
graphComponent.morphLayout(layout, '0.5s', genericData)
// an example data provider key for an ItemCollection:
// the corresponding provider returns true for each node which is contained in the collection
const IncludedNodesDpKey = new NodeDpKey(YBoolean.$class, ExampleStage.$class, 'IncludedNodesDpKey')
// an example data provider key for an ItemMapping:
// the corresponding provider returns a number for each edge
const EdgeWeightDpKey = new EdgeDpKey(YNumber.$class, ExampleStage.$class, 'EdgeWeightDpKey')
// generate generic data
const genericData = new GenericLayoutData()
// add an ItemCollection for IncludedNodesDpKey
const includedNodes = genericData.addNodeItemCollection(IncludedNodesDpKey)
includedNodes.delegate = (node: INode) => 'IncludeMe' === node.tag
// add an ItemMapping for EdgeWeightDpKey
const edgeWeights = genericData.addEdgeItemMapping(EdgeWeightDpKey)
edgeWeights.mapper.set(edge1, 10)
edgeWeights.mapper.set(edge2, 20)
graphComponent.morphLayout(layout, '0.5s', genericData)
Although not recommended, using IGraph's way to bind data using IMapper<K,V> and IMapperRegistry is another way to provide data for layout algorithms. LayoutExecutor or morphLayout create data providers for each IMapper<K,V> and transparently map from a Node to its original INode.
Time Complexity
Time complexities shows time complexities for several of the most frequent tasks when working with the yFiles graph structure implementation.
Creation of graph elements takes constant time as does the removal of an edge. Removing a node, though, implies the removal of all its connecting edges first, so this task takes linear time, i.e., time proportional to the number of connecting edges. Also, all iteration is done in linear time. Checking whether a given node or edge belong to a graph is done in constant time, while testing if there is an edge connecting two nodes takes linear time.
| Task | Involved Type(s) | Complexity |
|---|---|---|