| Binding Data to Graph Elements | ||
|---|---|---|
| Prev | Chapter 4. Working with the Graph Structure | Next |
This page is from the outdated yFiles for Java 2.13 documentation. You can find the most up-to-date documentation for all yFiles products on the yFiles documentation overview page.
Please see the following links for more information about the yFiles product family of diagramming programming libraries and corresponding yFiles products for modern web apps, for cross-platform Java(FX) applications, and for applications for the Microsoft .NET environment.
The concept of data accessors comprises two aspects which are commonly used in
different scenarios.
To bind supplemental data to graph elements that should be read-only, an
implementation of interface
DataProvider![]() suffices.
We will call these implementations "data providers" subsequently.
A data accessor with full read/write behavior, though, additionally implements
interface DataAcceptor
suffices.
We will call these implementations "data providers" subsequently.
A data accessor with full read/write behavior, though, additionally implements
interface DataAcceptor![]() .
The yFiles library knows these implementations as "maps," and has two dedicated
interfaces already defined,
NodeMap
.
The yFiles library knows these implementations as "maps," and has two dedicated
interfaces already defined,
NodeMap![]() and
EdgeMap
and
EdgeMap![]() .
Both extend interface DataMap
.
Both extend interface DataMap![]() which is a
combination of interfaces DataProvider and DataAcceptor.
which is a
combination of interfaces DataProvider and DataAcceptor.
Applying the two semantics it is, e.g., possible to restrict certain callees to "immutable" data, while others are allowed to make changes.
Observe that both interface NodeMap and EdgeMap show identical signatures on their respective methods, using java.lang.Object instead of either y.base.Node or y.base.Edge as the parameter type for their key. Actual implementations should nevertheless ensure that the keys provided have correct type.
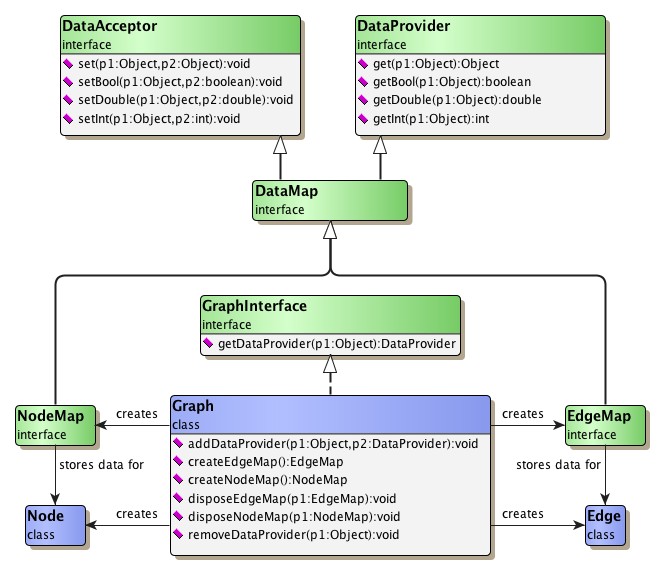
Figure 4.7, “The concept of data accessors” gives a brief overview of the classes involved in the basic concepts of maps and data providers.
Common to all data accessor implementations which are offered by the yFiles library is that they cover all elements of a set, i.e., a node map provides values for all nodes from a graph (however, these may all be default values when there hasn't been anything stored yet). Example 4.12, “Storing and retrieving data associated with a node” shows how node maps are used to store and retrieve arbitrary data.
Example 4.12. Storing and retrieving data associated with a node
// 'graph' is of type y.base.Graph.
// 'labelNodeMap' is of type y.base.NodeMap.
// 'counterNodeMap' is of type y.base.NodeMap.
// Bind a label to the first node of the node set.
// The bound data actually is of type java.lang.String.
labelNodeMap.set(graph.firstNode(), "I am the first node!");
// Increase the value stored in 'counterNodeMap' for the last node.
// The bound data is an int.
counterNodeMap.setInt(graph.lastNode(),
counterNodeMap.getInt(graph.lastNode()) + 1);
// Print out the label of the first node.
System.out.print("The name of the first node is: ");
System.out.println(labelNodeMap.get(graph.firstNode()));
Table 4.2, “Comparing map implementations” lists the differences of some data accessor implementations.
Table 4.2. Comparing map implementations
| Domain | Memory | Performance | Note | |
|---|---|---|---|---|
| Default maps | Multi-purpose | o | + | Need cleanup. |
| Index-based maps | Single-purpose | ++ | ++ | Require the underlying container to remain unaltered. |
| HashMap backed maps | Multi-purpose | + | o | Work well for sparse data. |
For a code example comparing the different map implementations see also NodeMapTest.java from the tutorial demo applications.
Although writing customized implementations for interfaces NodeMap or EdgeMap is easy, the most frequently used way to get these is conveniently provided by class Graph. Example 4.13, “Creating default node maps” shows one of the two methods that both return default implementations of these interfaces which can be used for most purposes and data types.
The maps returned by these methods hold exactly one value for a given key, i.e., no matter how many calls to any of the setter methods are issued for a given key, only the last value set will be held. Also, the type of the key given with a setter method is restricted to the respective type of graph elements, i.e., restricted to Node or Edge. The type of the value though, is not restricted to be same over the range of all nodes, for example. In fact, it would be perfectly legal to set a double value with one node, and boolean values with every other. This, however, is strongly discouraged, since it definitely leads to problems when the values will be retrieved.
Default map implementations can be created at any time, even when the graph is empty. From the moment of creation on, they will cover all graph elements from the respective set, as well as all respective elements created by the graph thereafter. However, these maps cannot cover elements that are hidden at the time of creation.
Note that these default implementations have to be properly disposed of after usage to release the allocated resources. To this end, class Graph has appropriate methods for either kind of default implementations.
Example 4.13. Creating default node maps
// 'graph' is of type y.base.Graph.
// Obtain a new y.base.NodeMap default implementation from the graph.
NodeMap nodeMap = graph.createNodeMap();
// Set values for some of the nodes.
nodeMap.setDouble(graph.firstNode(), 3.14);
nodeMap.setDouble(graph.lastNode(), 42.0);
// Print the values stored in the node map.
for (NodeCursor nc = graph.nodes(); nc.ok(); nc.next())
{
System.out.print("Node " + nc.node() + ": ");
System.out.println(nodeMap.getDouble(nc.node()));
}
// Finally release the resources previously allocated by the createNodeMap()
// method.
graph.disposeNodeMap(nodeMap);
In addition to using the default map implementations provided by class Graph,
there are further ways to create either maps or data providers.
For example, data providers can be implemented so that the actual data is only
implicitly defined, i.e., it is calculated on the fly when the value is asked
for.
This way, it is possible to "store" large amounts of data without having any
memory be allocated.
Example 4.14, “Using class DataProviderAdapter to create customized data providers” demonstrates how to use class
DataProviderAdapter![]() to elegantly define a
custom DataProvider implementation.
to elegantly define a
custom DataProvider implementation.
Example 4.14. Using class DataProviderAdapter to create customized data providers
// Define a DataProvider implementation that for each node in the graph returns
// an int that is the square of the node's index.
final DataProvider implicitDataProvider = new DataProviderAdapter() {
// This implementation provides only ints.
public int getInt(Object dataHolder) {
if (!dataHolder instanceof Node) {
throw new UnsupportedOperationException("Key has wrong type.");
}
final Node node = (Node)dataHolder;
return (node.index() * node.index());
}
};
// Define a DataProvider implementation that for each edge in the graph returns
// a distance value that is the difference of the values returned by
// implicitDataProvider for the source and target node.
final DataProvider edgeLengthProvider = new DataProviderAdapter() {
// This implementation provides only ints.
public int getInt(Object dataHolder) {
if (!dataHolder instanceof Edge) {
throw new UnsupportedOperationException("Key has wrong type.");
}
final Edge edge = (Edge)dataHolder;
return (implicitDataProvider.getInt(edge.target()) -
implicitDataProvider.getInt(edge.source()));
}
};
// Display the values "stored" (i.e., calculated on the fly) for each edge.
for (EdgeCursor ec = graph.edges(); ec.ok(); ec.next()) {
System.out.print("Edge " + ec.edge() + ": ");
System.out.println(edgeLengthProvider.getInt(ec.edge()));
}
Class DataProviders![]() from package y.util
offers a set of static methods to conveniently create several specialized data
provider implementations for either nodes or edges.
For instance, there are methods to create data providers from constant values,
from given arrays, or from existing data providers.
from package y.util
offers a set of static methods to conveniently create several specialized data
provider implementations for either nodes or edges.
For instance, there are methods to create data providers from constant values,
from given arrays, or from existing data providers.
Class Maps![]() from package y.util provides a
set of static methods to conveniently create several specialized map
implementations:
from package y.util provides a
set of static methods to conveniently create several specialized map
implementations:
The
createNodeMap![]() and
createEdgeMap
and
createEdgeMap![]() methods that take java.util.Map implementations and
return either a NodeMap or an EdgeMap view of the given instances.
Basically, this allows for any valid java.util.Map implementation, e.g.,
java.util.HashMap or
java.util.TreeMap, to be used in conjunction with the
yFiles graph implementation.
methods that take java.util.Map implementations and
return either a NodeMap or an EdgeMap view of the given instances.
Basically, this allows for any valid java.util.Map implementation, e.g.,
java.util.HashMap or
java.util.TreeMap, to be used in conjunction with the
yFiles graph implementation.
The various
createIndexNodeMap![]() and
createIndexEdgeMap
and
createIndexEdgeMap![]() methods return map implementations that are fast and at the same time use
little memory.
methods return map implementations that are fast and at the same time use
little memory.
HashMap implementations are true multi-purpose data holders, there is no restriction to the type of the keys nor the type of the values. Particularly, the keys are not restricted to graph elements. Compared to the default implementations of interface NodeMap and EdgeMap provided by class Graph they are generally a bit slower. However, their memory usage is proportional to the amount of the data that is actually associated with the entities.
Map implementations backed by an instance of type java.util.HashMap are especially suited for sparsely distributed data, i.e., only few entities of a domain have non-null data associated with them.
Index-based map implementations are very fast and use only little memory, their drawback, however, is that once instantiated their values are restricted to the type given at creation time. More important though, all index-based containers require the respective set of graph elements to remain unaltered, i.e., there are no operations allowed that change the sequence of the graph elements in any way.
Example 4.15. Using yFiles convenience classes to create edge maps
// 'graph' is of type y.base.Graph.
// Create an edge map that holds a boolean value for each edge from
// the edge set of the graph.
EdgeMap map = Maps.createIndexEdgeMap(new boolean[graph.E()]);
// Store some data into the edge map.
// (For each edge the map will contain the boolean value indicating whether
// the edge points from a node with a lower index to a node with
// a higher index.)
for (NodeCursor nc = graph.nodes(); nc.ok(); nc.next()) {
for (EdgeCursor ec = nc.node().edges(); ec.ok(); ec.next()) {
Edge e = ec.edge();
map.setBool(e, e.source().index() < e.target().index());
}
}
Successfully using a data accessor requires a kind of "agreement" on the type the data accessor holds. More precisely, storing the value for a key and retrieving the value thereafter has to be done using setter and getter methods of matching type. The result when using setter/getter methods with non-matching types highly depends on the specific data accessor implementation. Example 4.16, “Successfully using data accessors” demonstrates the proper usage of a data accessor.
This rule furthermore implies that a self-made data accessor has to provide the proper getter (and/or setter) methods when it is used as a parameter to an algorithm.
Example 4.16. Successfully using data accessors
// 'graph' is of type y.base.Graph. // Get a default NodeMap implementation from the graph. NodeMap nm = graph.createNodeMap(); // Store values for some chosen nodes. nm.setBool(graph.firstNode(), true); nm.setBool(graph.lastNode(), true); // Retrieve the stored values. // WRONG. WRONG. WRONG. // Boolean values cannot be retrieved as ints. int firstValue = nm.getInt(graph.firstNode()); int lastValue = nm.getInt(graph.lastNode()); // Retrieve the stored values. // RIGHT. boolean first = nm.getBool(graph.firstNode()); boolean last = nm.getBool(graph.lastNode());
|
Copyright ©2004-2016, yWorks GmbH. All rights reserved. |